A topic that keeps coming up for me recently is understanding the difference between duplicating and referencing a query in Power Query. I felt it was worth while capturing my thoughts on how to explain the two.
What do they do?
When you duplicate a query it takes a copy including all of the applied steps. You can makes changes or add steps to the duplicate and it will not have any impact on the original query. The two queries exist independently of each other once they’ve been duplicated.
When you reference a query, it doesn’t copy all of the steps. It will create a query with one step that gives the end result of the original query. You can add additional steps to your reference query if you wish. If you make any changes to the original query, these will be passed on to the reference query too, so the queries are still linked.
Query confusion
A popular misconception is that a reference query makes fewer calls back to the source data. That somehow the original query will only be run once, the data cached and that the reference query then utilises this cache to load its data. Especially for relational database sources, this simply isn’t true. It seems to be such a commonly held belief that even Microsoft have added a page to their documentation to explain this.
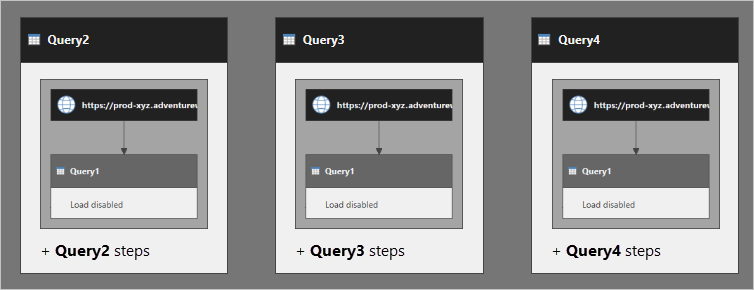
My way to try and explain this succinctly is as follows:
When you reference a query you are not referencing the data, you are referencing the code.
If you’re familiar with the programming concept of DRY principle (Don’t Repeat Yourself), using a reference query can be one way to re-use something you’ve already built.
Why would you use a duplicate query?
A great use case for duplicate queries was recently explained by Brian Julius on his LinkedIn page.
He suggested using a duplicate query is a great way to test changes to a particular query to make sure you get the right results, whilst still maintaining a copy of the original steps. This can be particularly useful if using the advanced editor, where it can be easier to introduce mistakes.
How about a reference query?
Two particular use cases spring to mind. The first being when you might need to derive a fact table and dimension tables from a single database table. It makes sense in this scenario to create a query that brings in the full table, and then write a series of reference queries to turn the data in to a better shape for reporting. The great thing about this approach is that if the source table needs to swap to a different location, you can change it once in the initial query and it will flow through to all the reference queries that use it.
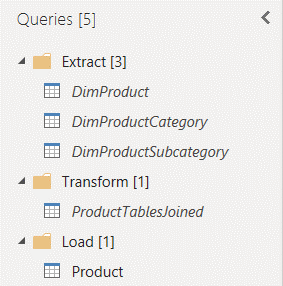
The other way I often use reference queries is as a means to show some data lineage. When I’m doing work in Power Query, be that in Power BI desktop of whilst using Dataflows I tend to set up three folders;
- One labelled “Extract” where I bring in my source data tables and leave them untouched.
- One labelled “Transform” where I will create reference queries that point to my “Extract” folder and perform things such as merges, appends and aggregation.
- One labelled “Load” where I create reference queries that point to my “Transform” folder to create the final form of my tables, maybe removing unwanted columns and performing any renaming.
Queries in both the Extract and Transform folders have the “Enable Load” option switched off. I have no need to load the data in those queries, they’re there to help me build towards my final tables.
Here’s an example where I’m joining the product tables from the Contoso dataset to create a denormalised Product dimension table.
In the era of the Data Lakehouse I am tempted to change this naming convention to either Bronze/Silver/Gold or Raw/Base/Curated.
Is there a cache?
I did once answer this question as “no”, but in reality it is more nuanced than that. Throughout the Power Query editing experience, yes some things such as query results are cached. That doesn’t happen during a dataset load though, it’s just part of the development experience.
But in this guest appearance on Guy In A Cube, Chris Webb demonstrates a way you can cache query results to use as intermediary steps for further processing downstream. This is using an API data source though and isn’t something I believe works with relational databases.
Conclusion
So, that’s how duplicate and reference queries work and how you may wish to use them. Just please don’t fall in to the trap of believing that reference queries are somehow magically more efficient and process less data. What are your favourite practices for using duplicate and reference queries?



1 Comment
Belinda Allen · January 30, 2023 at 12:39 pm
Great post Johnny. I often find a need for references when I want to separate data. Often in an ERP system, Customers, Contancts and/or Prospects will reside in a single table. Or GL Accounts and Units Accounts; and sometimes Vendors and Customers. I use the initial query to remove the extra columns, like Created By, Created Date, etc. Then each referenced query is easier to work with.